最近同事请假,我帮忙支援问答社区,其中有一份统计工作比较令人苦恼,因为需要将问答的标题、地址、是否回答等信息统计为表格,然后每天通过邮件发给领导。因为没有相关工具,需要手动将当天的问题信息一个一个复制到表格中,十分浪费时间。为此,写了个小工具将任意时间段的内容统计并自动导出为excel文件,从此方便了许多,特写文章记录心酸历程。
分析
首先分析下需要准备的内容,每天发邮件内的表格如图。

表内的标题是可以点击的,当点击后需要转跳到相关页面。那么就需要标题和链接这两个参数。我们还需要是否回答这个参数,以及当前问题的标签,为了方便判断当前问题是什么时候提问的,还需要时间这个参数。总计5个参数,接下来,看看如果用爬虫的话,我们能不能在社区抓到这几个数据?
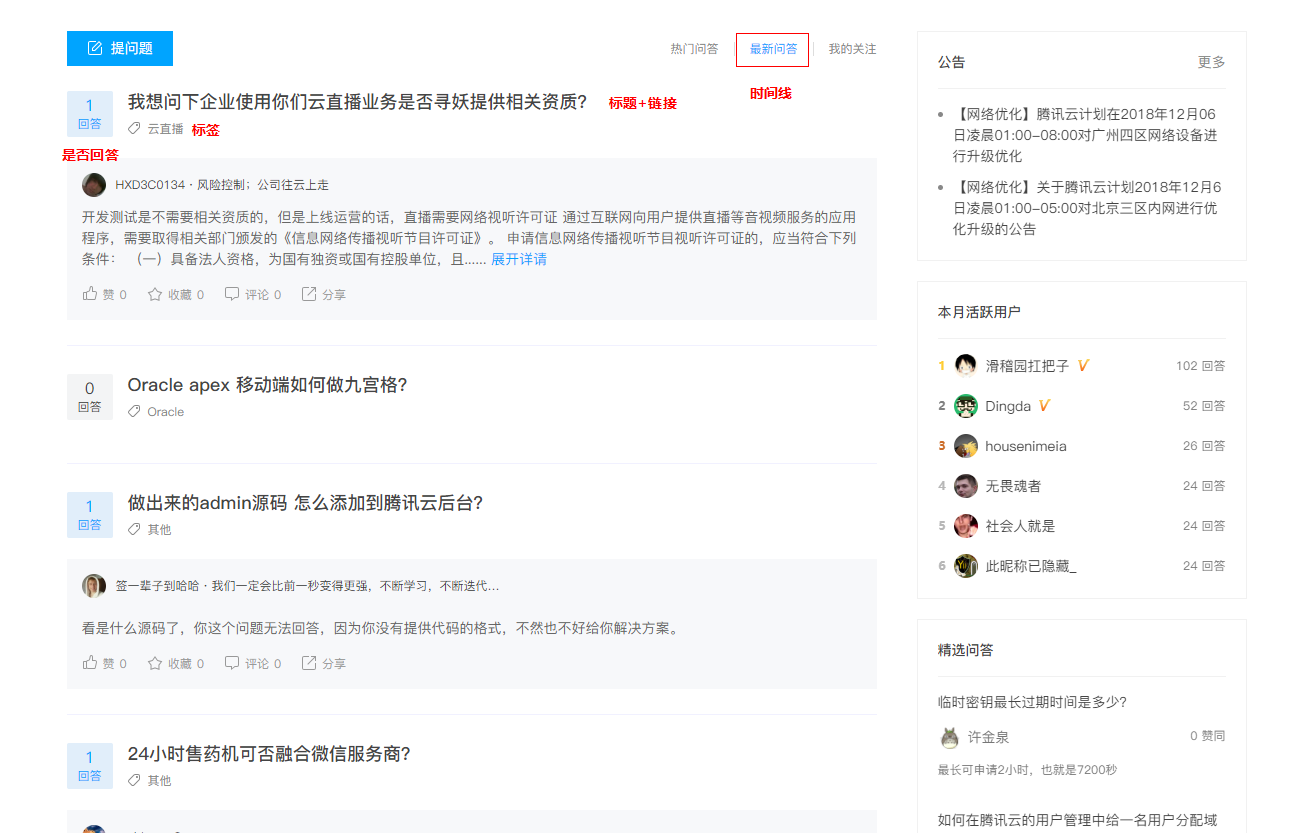
分析下问答社区,我们看到,图中的几个参数基本上都能在首页获取到,就是这个时间藏的比较深,在前端页面并没有返回给用户,需要点击问题才能看到提问时间。还有点麻烦,需要模拟成浏览器,再点击地址,最后用正则或者其他方式获取数据。不仅麻烦效率还低啊,然后继续看网页代码。
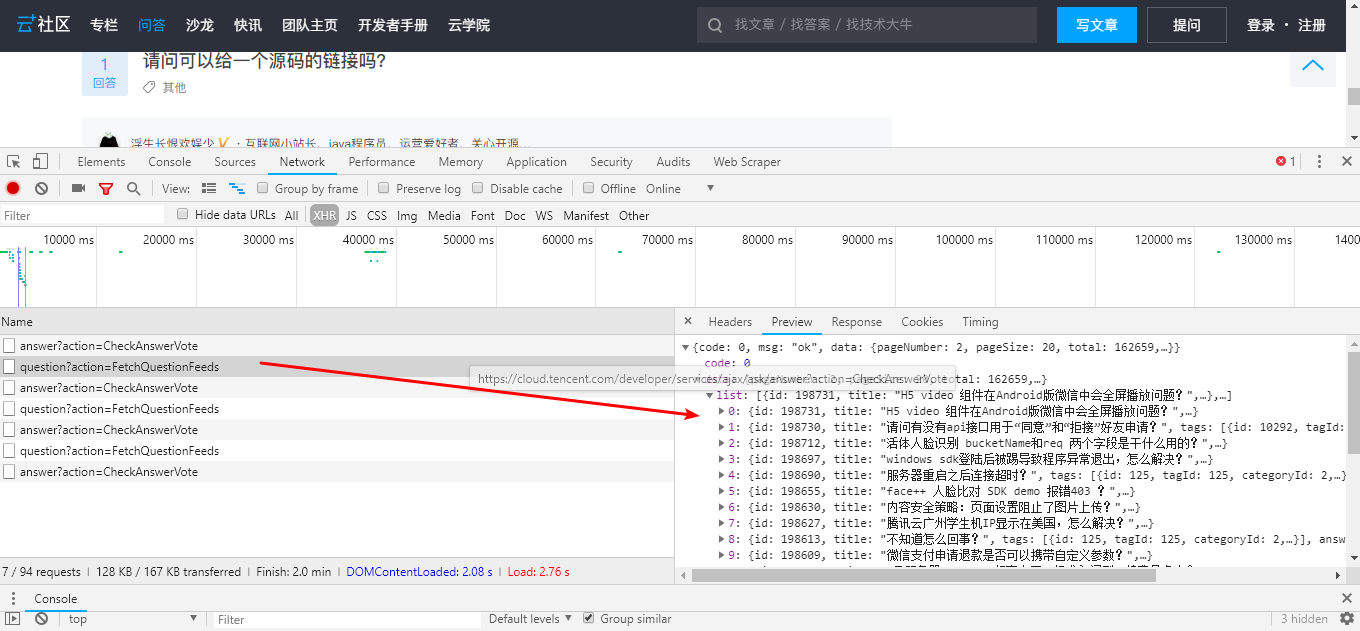
突然发现问答社区的内容都是通过API接口去获取的,通过POST去请求某个地址,然后在本地解析这些数据,最重要的是,这些数据是json数据。那么我也可以通过这些数据去做统计呀,研究下json数据。
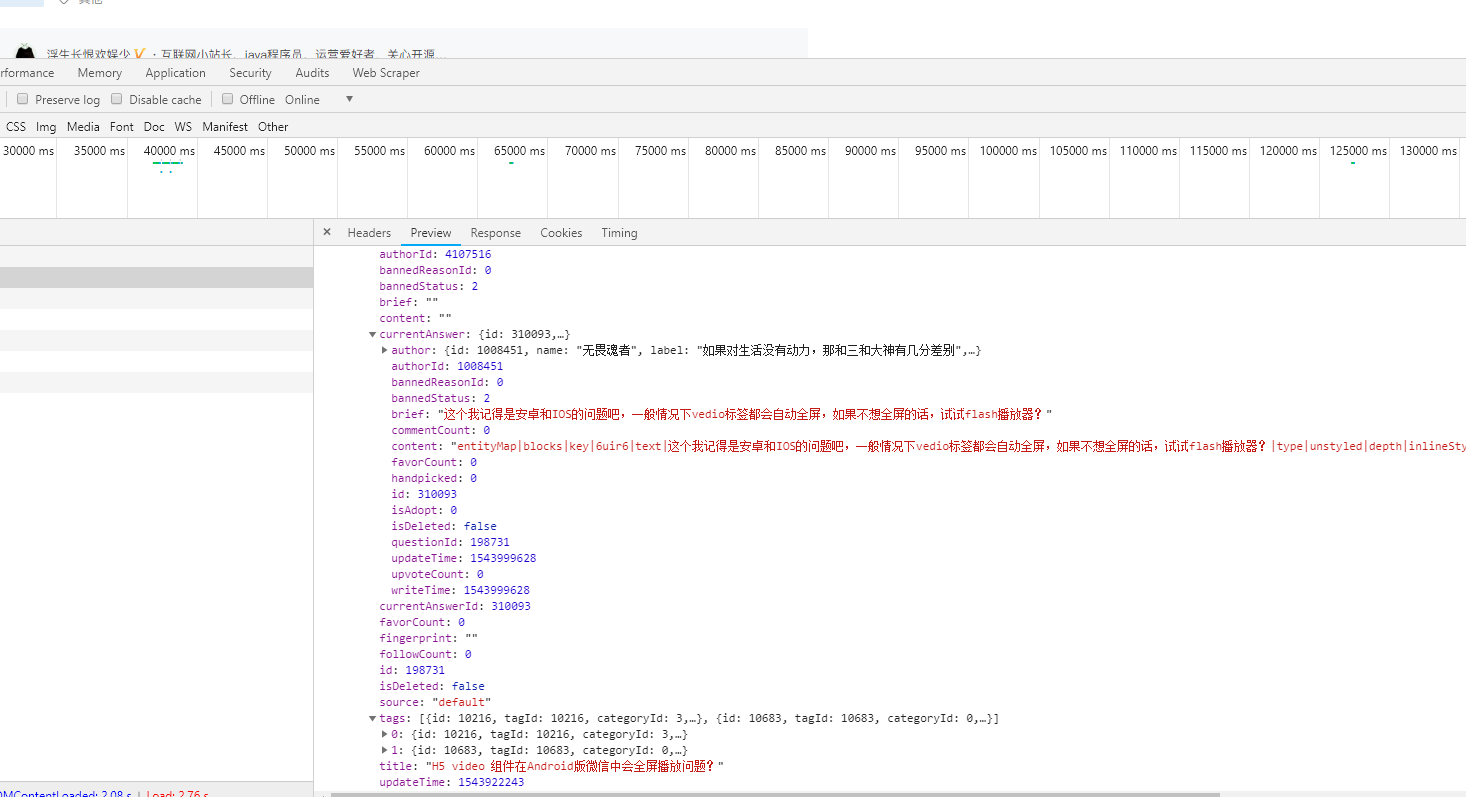
我们看到数据中有标题数据title,标签tags,回答数answerCount,没有时间和链接啊,等下研究下,有UTC时间戳writeTime和updateTime。通过这两个数可以转换成当前时间,链接呢?分析下问答社区的地址,都是https://cloud.tencent.com/developer/ask/加一段数字。那么这个数字就是问题ID,在json数据中显示为id。有了这些数据,我可以向腾讯云的接口去请求这些数据,然后等其返回json数组,然后我再本地解析不就OK了嘛~看起来蛮简单的。
request请求
通过Chrome浏览器,我们可以轻轻松松的查看到请求的参数,如图。
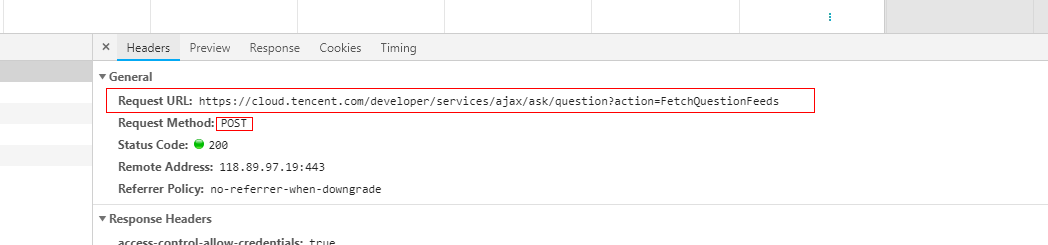

请求数据也是json,简单分析下就知道,pageNumber是请求页,pageSize是请求数,queryType是请求类型。打开API测试软件postman,测试下接口能不能用。
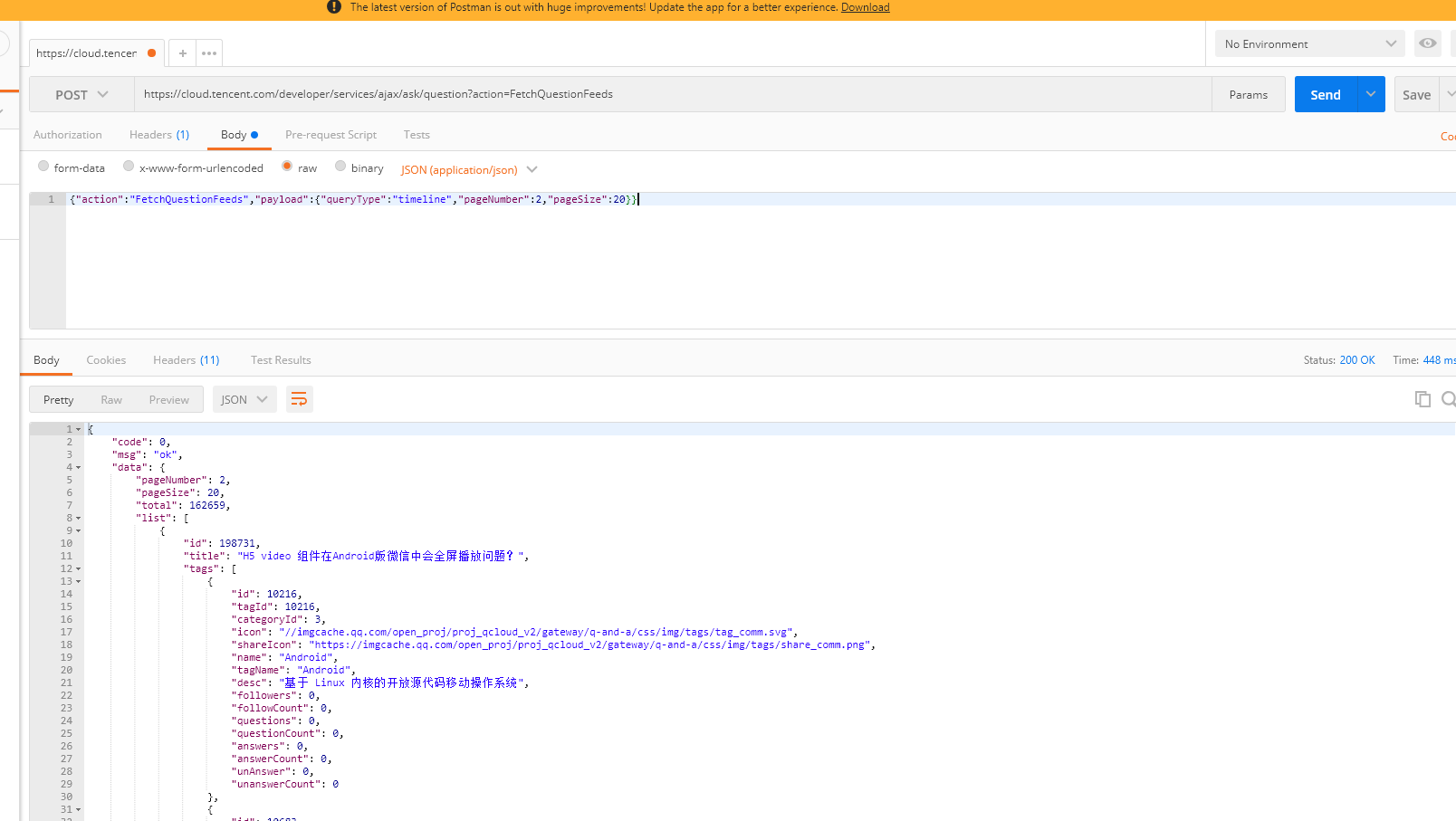
运气不错,直接POST参数过去就能返回相关值,看来社区没有做限制,尝试修改pageSize和pageNumber参数,发现pageSize最大值为50。本来还想着一次请求几百条数据,然后做筛选呢,没办法了,只能动态修改pageNumber参数去做处理了。
代码
写代码的过程真的是辛酸史啊……人呐,就是欠,本来可以用PHP以及Python轻松搞定的事情,非要用NodeJS。然后遇到了回调地狱……当然这是后话,先写最基础的代码。
因为要做request请求,PHP及Python都支持的比较好,但是想到要导出excel文件,使用NodeJS的NPM包,想必更简单,于是决定用NodeJS去写。
首先就是发起request请求了,通过npm install request安装完相关依赖。打开vscode,写下下面的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| var request = require("request");
var options = { method: 'POST',
url: 'https://cloud.tencent.com/developer/services/ajax/ask/question',
qs: { action: 'FetchQuestionFeeds' },
headers:
{ 'cache-control': 'no-cache',
'content-type': 'application/json' },
body:
{ action: 'FetchQuestionFeeds',
payload: { queryType: 'timeline', pageNumber: 1, pageSize: 50 } },
json: true };
request(options, function (error, response, body) {
if (error) throw new Error(error);
console.log(body);
});
|
没有难度嘛(天真),请求数据顺利打印出来,接下来就是处理了。因为返回的body数据是json格式,可以直接将其解析出来。
1
2
3
4
| request(options, function (error, response, body) {
console.log(body.code);
console.log(body.msg);
console.log(body.data.pageNumber);
|
这样就能解析其是否成功,但是为什么console.log(body.data.list.title);就不能显示呢?因为以前没用过json数据处理,这里的json数组是一个多维数组,更懵逼了,搜了几个小时资料,发现console.log(body.data.list[0].title)能显示第一条问答的标题,console.log(body.data.list[1].title)能显示第二条数据,那么我可以通过枚举法将内容解析出来。用for循环。
1
2
3
| for(i=0;i<50;i++){
console.log(body.data.list[i].title)
}
|
这样就能循环输出标题了,同理,输出时间,id,回答数。
1
2
3
4
5
6
| for(i=0;i<50;i++){
console.log(body.data.list[i].title)
console.log(body.data.list[i].writeTime)
console.log(body.data.list[i].id)
console.log(body.data.list[i].answerCount)
}
|
将ID拼接为链接,然后将UTC时间转换为正常人能看懂的时间
1
2
| data_url = "https://cloud.tencent.com/developer/ask/" + body.data.list[i].id
dates = new Date(body.data.list[i].writeTime).toLocaleString()
|
接下来发现标签内也是数组,那么依然用for循环。但是提前并不知道标签数,所以需要知道标签的json长度,我们可以使用length方法。
1
2
3
4
| var data_tags = new Array()
for(tag_nums=0;tag_nums<body.data.list[i].tags.length;tag_nums++){
data_tags[tag_nums] = body.data.list[i].tags[tag_nums].tagName
}
|
难度并不大,然后使用默认的fs模块将其写成csv文件。
1
2
3
4
| var fs_integral = data_url + ',' + dates + ',' + body.data.list[i].title + ',' + body.data.list[i].writeTime + ',' +data_tags;
fs.appendFile('ask','\r\n' + fs_integral, function (err) {
if (err) throw err;
});
|
完整代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| var request = require("request");
var fs = require("fs");
var options = { method: 'POST',
url: 'https://cloud.tencent.com/developer/services/ajax/ask/question',
qs: { action: 'FetchQuestionFeeds' },
headers:
{ 'cache-control': 'no-cache',
'Content-Type': 'application/json' },
body:
{ action: 'FetchQuestionFeeds',
payload: { queryType: 'timeline', pageNumber: 1, pageSize: 50 } },
json: true }
request(options, function (error, response, body) {
if (error) throw new Error(error)
var data_arr = new Array()
for (i=0; i < data_json.data.list.length ;i++){
var Date_cut = now_UTC - data_json.data.list[i].writeTime
var data_tags = new Array()
data_tiele = data_json.data.list[i].title
data_id = "https://cloud.tencent.com/developer/ask/" + data_json.data.list[i].id
if (data_json.data.list[i].answerCount>0){
data_answer = '是'
}else{
data_answer = '否'
}
data_writeTime = new Date(data_json.data.list[i].writeTime*1000).toLocaleString()
for(a=0;a<data_json.data.list[i].tags.length;a++){
data_tags[a] = data_json.data.list[i].tags[a].tagName
}
var data_set = [data_writeTime,data_id,data_tiele,data_answer,data_tags]
data_arr.push(data_set)
}
fs.appendFile('data_arr','\r\n' + fs_integral, function (err) {
if (err) throw err;
});
});
|
(注:因为文章写的比较晚,上面的代码是重写的,没有测试,大家大概能看懂意思就行)
本来想着写完了用了两天发现几个问题:
- 输出的文件编码错误,用excel打开会乱码,需要手动改,很麻烦。
- 只能输出前50条内容,如果想查看更多问题,需要改代码。
- 不能按照自己想要的内容输出,在excel处理时,还需要调整一些才能使用。
- 代码逻辑混乱,改起来有点崩溃。
- 不能按照天数输出内容,鸡肋。
首先是导出excel问题,这个简单,安装node-xlsx依赖即可。接下来是输出前50问题,再加一个for循环应该能解决,比较简单吧(天真)。第三个问题,难度也不大,将输出内容通过文本形式保存,然后使用excel的函数HYPERLINK将其连接起来。第四个无解,除非重写。第五个,我可以通过当前UTC时间和发布的UTC时间来判断问题发表是几秒前发布的的,如果这个秒数小于24小时,就将这条问题输出到excel。这样就解决了按照天数输出问题,我可以直接输出24小时内的问题,更新下代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| var request = require("request");
var xlsx = require('node-xlsx');
var fs = require("fs");
now = new Date()
now_UTC = now.getTime()/1000
var options = { method: 'POST',
url: 'https://cloud.tencent.com/developer/services/ajax/ask/question',
qs: { action: 'FetchQuestionFeeds' },
headers:
{ 'cache-control': 'no-cache',
'Content-Type': 'application/json' },
body:
{ action: 'FetchQuestionFeeds',
payload: { queryType: 'timeline', pageNumber: 1, pageSize: 50 } },
json: true }
request(options, function (error, response, body) {
if (error) throw new Error(error)
data = JSON.stringify(body)
data_json = JSON.parse(data)
var data_arr = new Array()
for (i=0; i < data_json.data.list.length ;i++){
var Date_cut = now_UTC - data_json.data.list[i].writeTime
if (Date_cut < 86400 ){
var data_tags = new Array()
data_tiele = data_json.data.list[i].title
data_id = "https://cloud.tencent.com/developer/ask/" + data_json.data.list[i].id
if (data_json.data.list[i].answerCount>0){
data_answer = '是'
}else{
data_answer = '否'
}
data_writeTime = new Date(data_json.data.list[i].writeTime*1000).toLocaleString()
for(a=0;a<data_json.data.list[i].tags.length;a++){
data_tags[a] = data_json.data.list[i].tags[a].tagName
}
hyperlink = '=HYPERLINK("' + data_id + '","' + data_tiele + '")'
var data_set = [data_writeTime,hyperlink,data_answer,data_tags]
data_arr.push(data_set)
}
}
var buffer = xlsx.build([{name: "mySheetName", data: data_arr}]);
fs.writeFileSync('./'+ now.toLocaleDateString() +'.xlsx', buffer);
});
|
这个只能解决输出当天的问题,当天提问数大于50,这个工具就失效了,功能还是明显的鸡肋。我想到可以使用for循环去改变pageNumber的数值,然后将返回的data值统一存起来,等请求完了处理。理想很丰满,现实很骨感……改完代码发现每次输出的都是当前pageNumber页面的问题数,以前的数据全没了。那么我可以将data存在数组中啊,在改下代码。哈?数组为空?????为啥,原来request请求返回是由回调函数返回的,我不能在回调函数外去调去回调函数的数据。之后我就陷入了两天的回调函数处理……
google和百度都翻遍了……根本没有找到NodeJS如何将回调函数中的数据返回在外面,然后通过其他函数去调用。突然,我看到了Promise方法和async/await方法,这也是我写本篇文章的原因,分享一下这两个方法是使用。原来,在NodeJS中,回调函数都是通过异步方法去写的,想去外面调用异步函数的内容,真是比登天还难。有了Promise方法和async/await顺顺利利解决了我无法在外部调用回调函数内数据的问题,修改request请求代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| var request = require('request');
var synchronous_post = function (){
var options = {method: 'POST',
url: 'https://cloud.tencent.com/developer/services/ajax/ask/question',
qs: { action: 'FetchQuestionFeeds' },
headers:
{ 'cache-control': 'no-cache',
'Content-Type': 'application/json' },
body:
{ action: 'FetchQuestionFeeds',
payload: { queryType: 'timeline', pageNumber: 1, pageSize: 50 } },
json: true };
return new Promise(function(resolve, reject){
request(options , function(error,response,body){
if(error){
reject(error);
}else{
resolve(body);
}
});
});
}
var extract_data = async function(){
data = await synchronous_post();
}
extract_data();
|
现在,我可以通过调用synchronous_post函数来实现同步调用异步,并将回调函数的数据赋予到其他变量中,依然按照以前的思路,重构下代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| var request = require('request');
var xlsx = require('node-xlsx');
var fs = require("fs");
var scanf = require('scanf');
console.log("请输入你要统计的小时数:")
var hours = scanf('%d');
var request_page_num = 1
var data_arr_loop = 0
var synchronous_post = function (){
var options = {method: 'POST',
url: 'https://cloud.tencent.com/developer/services/ajax/ask/question',
qs: { action: 'FetchQuestionFeeds' },
headers:
{ 'cache-control': 'no-cache',
'Content-Type': 'application/json' },
body:
{ action: 'FetchQuestionFeeds',
payload: { queryType: 'timeline', pageNumber: request_page_num, pageSize: 50 } },
json: true };
return new Promise(function(resolve, reject){
request(options , function(error,response,body){
if(error){
reject(error);
}else{
resolve(body);
}
});
});
}
var extract_data = async function(){
now = new Date()
now_UTC = now.getTime()/1000
var data_arr = new Array()
var data_arr_excel = new Array()
var circulation_state = 1
while(circulation_state == 1){
data = await synchronous_post();
data_arr.push(data.data)
var Date_cut_49 = now_UTC - data.data.list[49].writeTime
if (Date_cut_49 < 3600 * hours ){
circulation_state = 1
request_page_num++
}else{
circulation_state = 0;
}
}
while(data_arr_loop < request_page_num){
for(data_loop=0;data_loop < data_arr[data_arr_loop].list.length;data_loop++){
var Date_cut = now_UTC - data_arr[data_arr_loop].list[data_loop].writeTime
if(Date_cut < 3600 * hours){
var data_tags = new Array()
data_title = data_arr[data_arr_loop].list[data_loop].title
data_writeTime = new Date(data_arr[data_arr_loop].list[data_loop].writeTime*1000).toLocaleString()
data_url = "https://cloud.tencent.com/developer/ask/" + data_arr[data_arr_loop].list[data_loop].id
if (data_arr[data_arr_loop].list[data_loop].answerCount>0){
data_answer = '是'
}else{
data_answer = '否'
}
for(tag_nums=0;tag_nums<data_arr[data_arr_loop].list[data_loop].tags.length;tag_nums++){
data_tags[tag_nums] = data_arr[data_arr_loop].list[data_loop].tags[tag_nums].tagName
}
console.log(data_title,data_writeTime,data_url,data_answer,data_tags);
hyperlink = '=HYPERLINK("' + data_url + '","' + data_title + '")'
var data_excel = [data_writeTime,hyperlink,data_answer,data_tags]
data_arr_excel.push(data_excel)
}
}
data_arr_loop++
}
var buffer = xlsx.build([{name: "data", data: data_arr_excel}]);
fs.writeFileSync('./'+ now.toLocaleDateString() +'.xlsx', buffer);
}
extract_data();
|
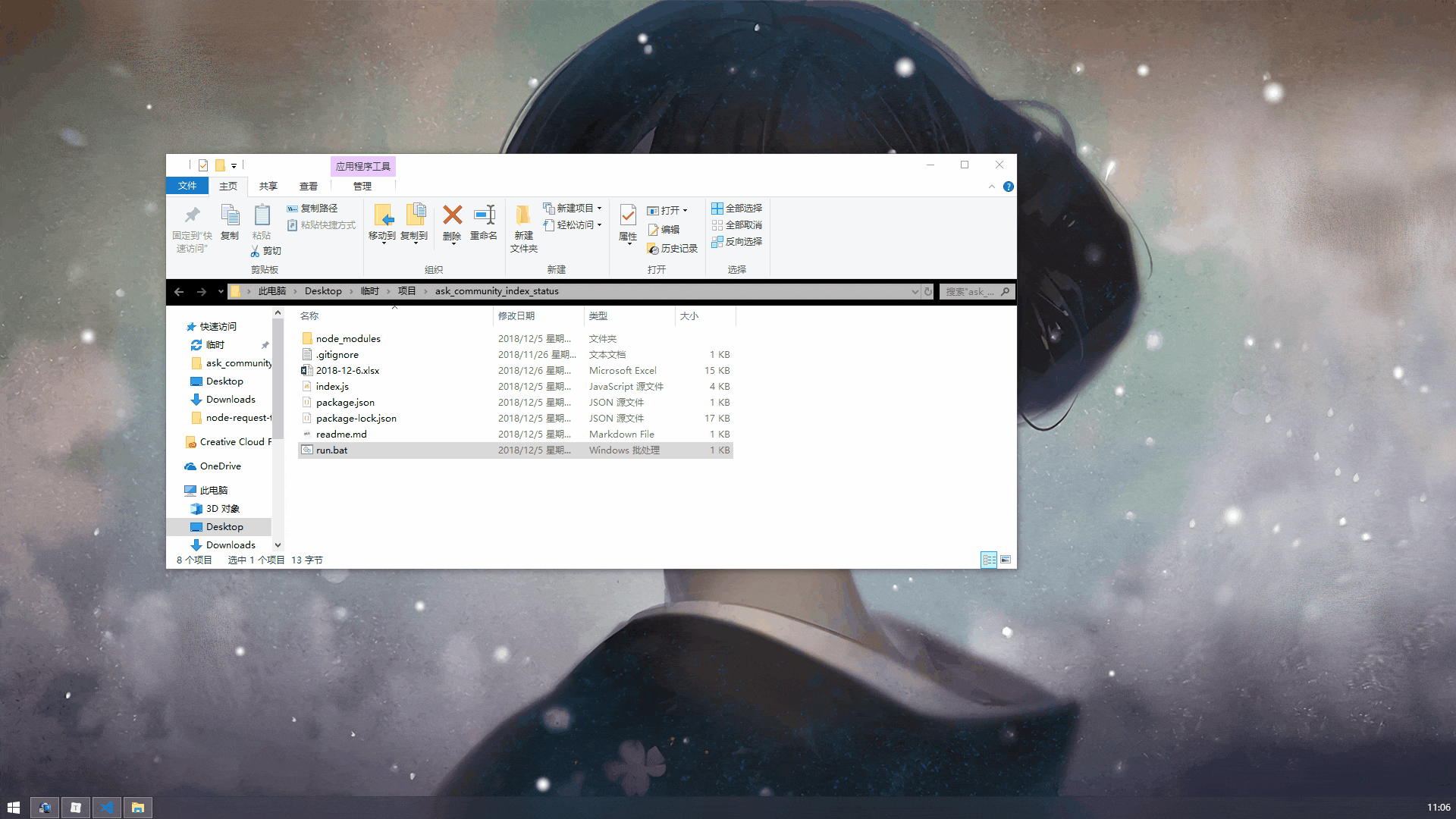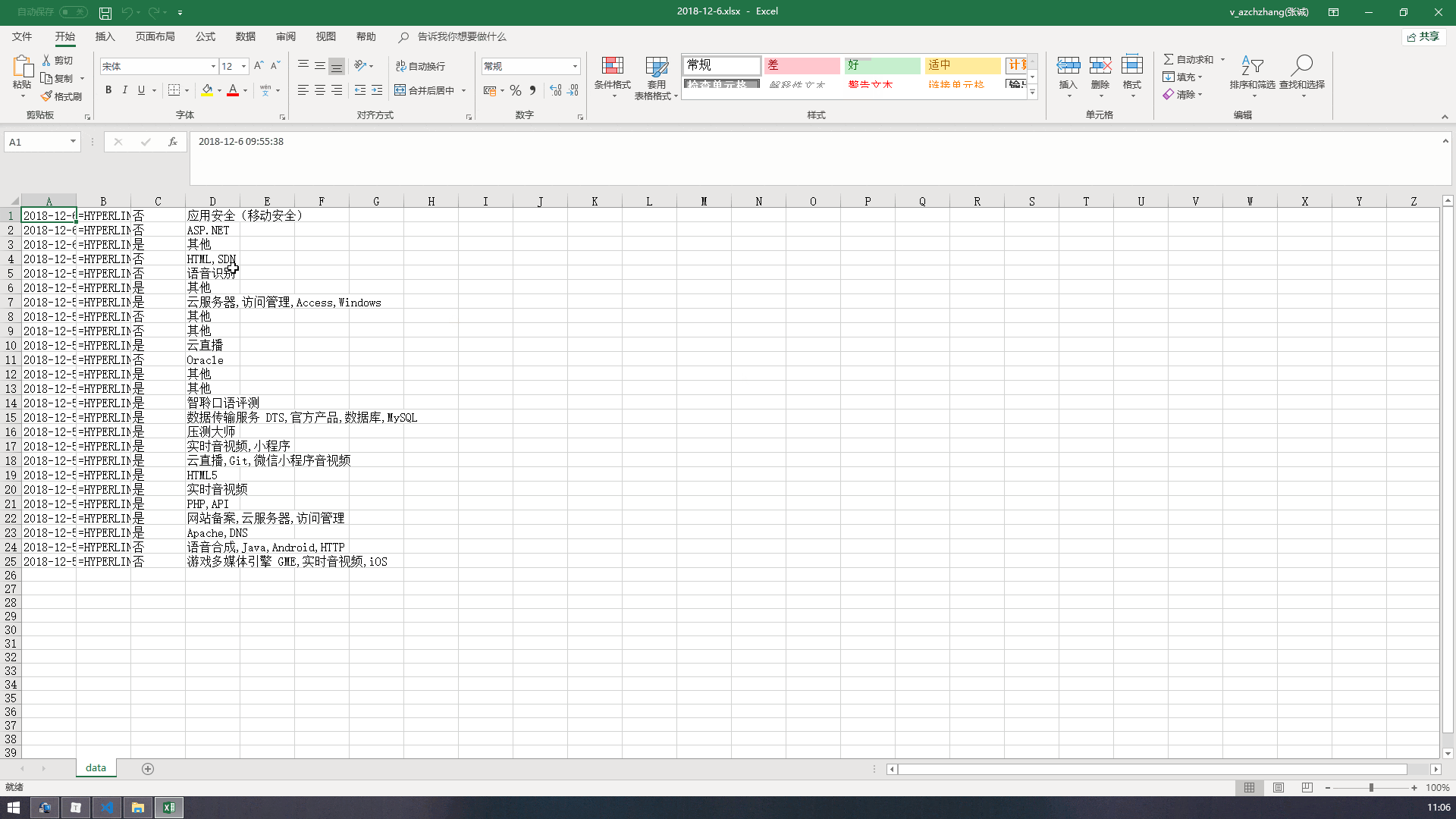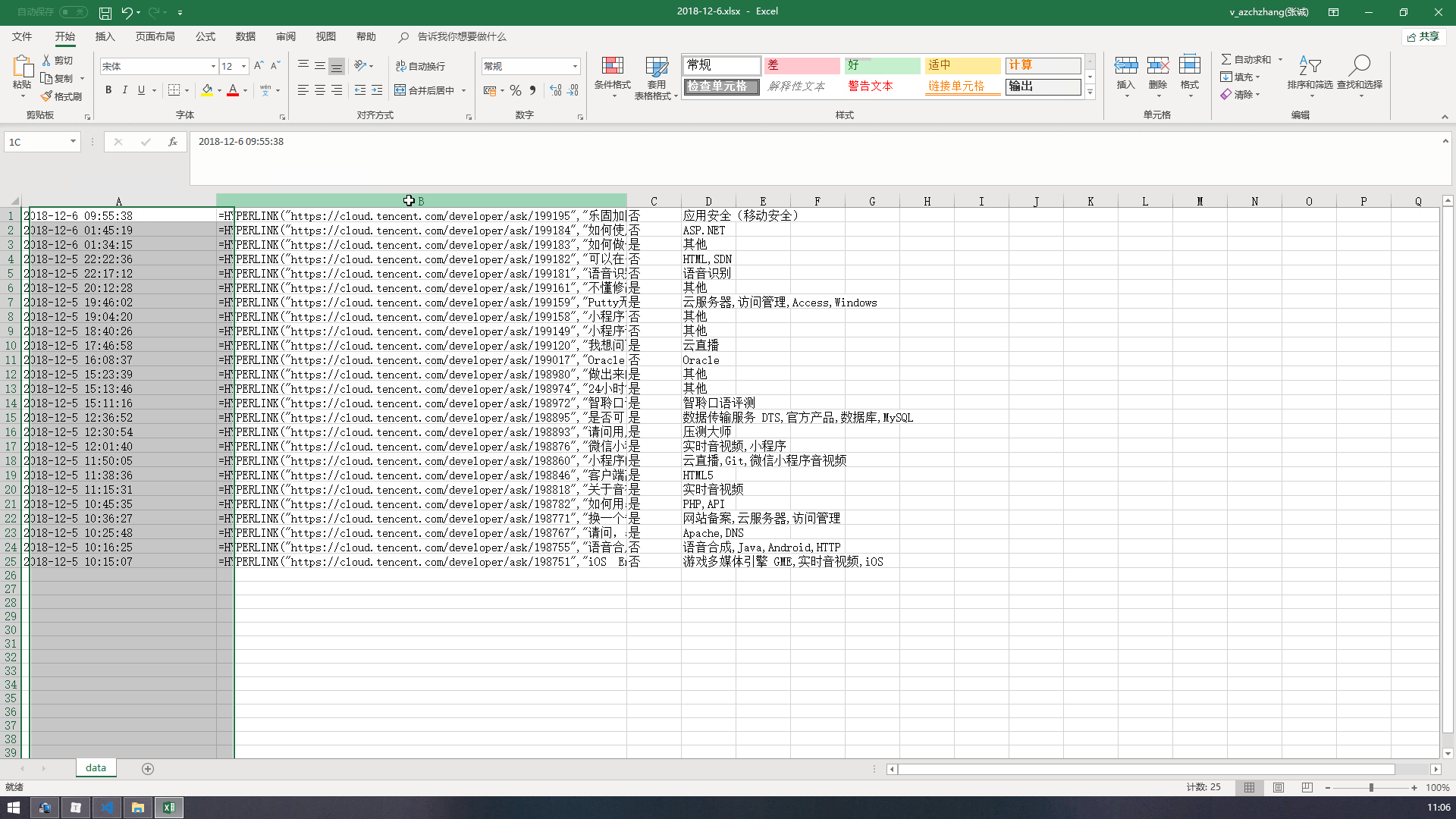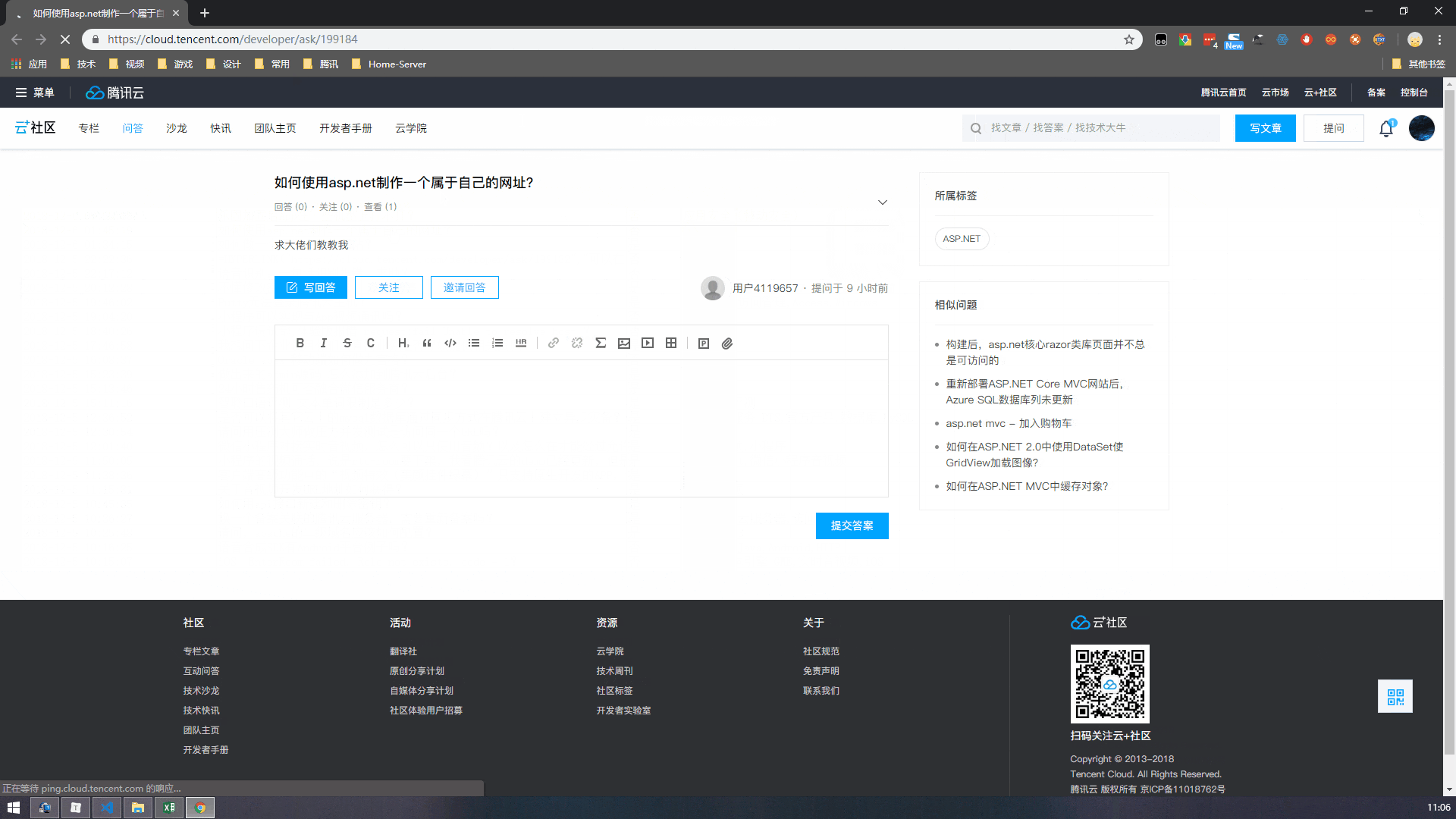
重写一遍神清气爽~演示效果如下(图片较大,耐心等待)。
总结
虽然项目很简单,但是学到了一些新的知识,学会了json的数据处理,学会了node异步变同步,这应该是我目前写过逻辑最复杂的脚本了,又啃了几天回调地狱的硬骨头。蛮开心的,将项目分享到了GayHub(https://github.com/Techeek/ask_community_index_status),欢迎对request,异步,json数据处理有疑问的同学前去讨论哦~
