
前言
最近在做知乎渠道的运营工作,一直抓不住用户的痛点,不知道该如何下手。为了增加粉丝及阅读数,我想到了用爬虫去抓取知乎内各话题的关注数,抓完后发现了很有意思的现象,固撰写本文分享。
爬虫
分析
我们先讲讲爬虫,这10w个网页我没有写代码去实现抓取,当时在上班,不想花太多时间去抓取这些内容(flag)。所以就采用Chrome浏览器的插件Web Scrape去实现抓取。
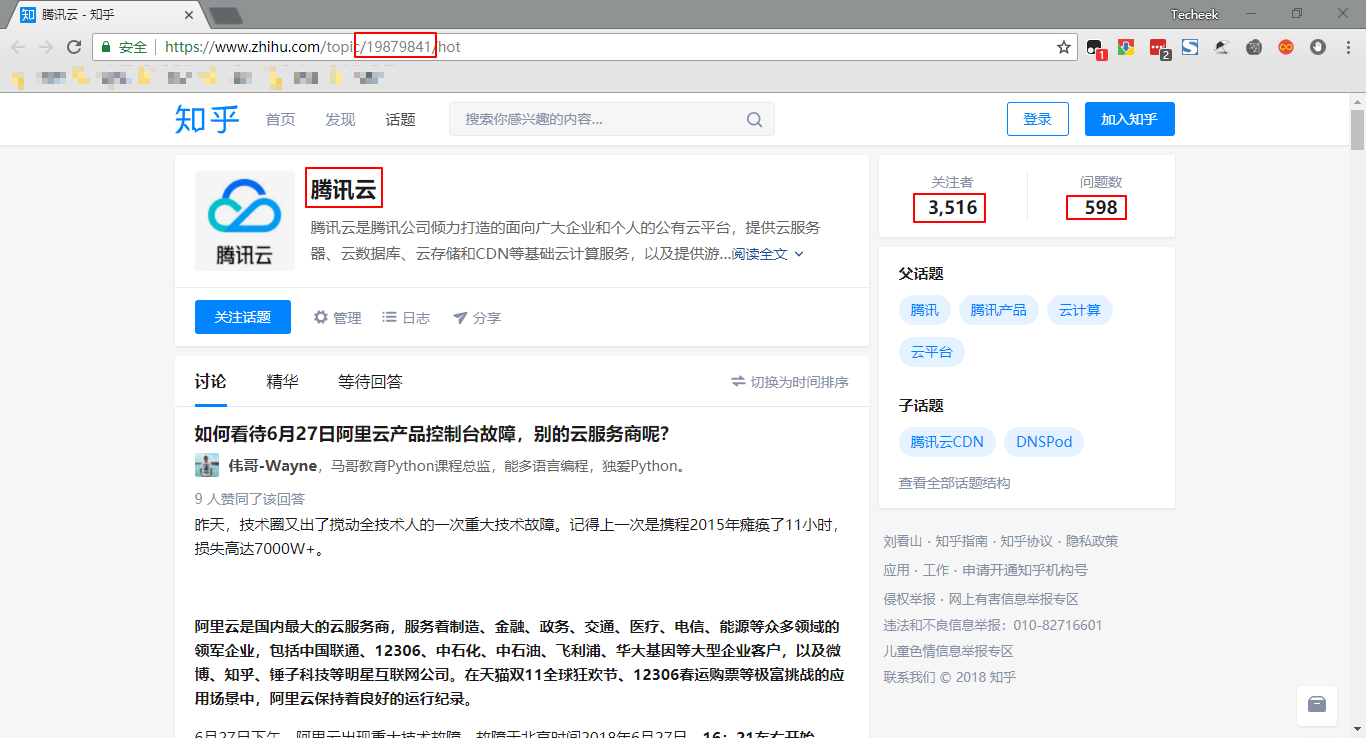
分析下知乎标签相关页面的逻辑吧。请看上图,着重分析几个点:
- 话题名称:腾讯云
- 话题关注者:3516
- 话题阅读数:598
- 话题ID:19879841
其中话题ID是爬虫需要关注的内容,每个话题的话题ID不同,我尝试了下,ID区间大概是从19590000~20210200,约62W个网站需要抓取。重点来了,知乎的话题ID无任何规律可寻,可能19879841是腾讯云的话题ID,但是19879842就变成了一个不存在的话题。在没有任何规律的情况下,我该如何使用Web Scraper去抓取数据呢?答案只有一个“穷举”。
穷举效率
我打算用Web Scraper去访问19590000~20210200的每一个页面,如果访问正常,则抓取相关数据,反之弃之。但是这里遇到一个问题,Web Scraper访问一个页面至少要3秒,62W个网站就是186w秒,换算下来至少需要21天,这不搞笑嘛?
为此我想了其他办法,能不能增加效率呢?比如多开几个进程去执行,说干就干,我拆分了将62w数据拆分成了20个组,算下来每组也就3.1w网页,这下只需要1天多就可以搞定啦!
然而理想很丰满,现实很骨感……
反爬虫和服务器性能
首先我买了台腾讯云的Window 2012 server 1H2G服务器去跑Web Scraper,跑了大概10分钟,发现知乎开始拒绝我了,需要输入验证码才能正确访问。额好吧,看来知乎确实开了反爬虫。总不可能我一直在旁边盯着看然后手动填写验证码吧?为此,我决定买一个拨号软件。让软件按照30s的频率去切换IP,这样我就能安心的看着爬虫去跑了。然而我又天真了,试用了国内各大所谓的换IP软件,一个比一个辣鸡!有时候拨号拨着拨着就自己停了!那我要你们何用!滚粗!
接着我看到淘宝有买拨号VPS的。Windows 7 2H2G 19元每天,行吧,尝试下,搭建爬虫环境,然后下了个PPPOE自动拨号的软件,依然按照30s的频率去跑。这下稳定了,看下表已经是半夜1点多了,睡觉。
第二天醒来,打开远程桌面,WTF!Chrome崩溃!额,好吧,20个进程看来对服务器压力还是蛮大的。换成10个线程,这样第二天下午就能看到数据了,想想还有点小激动呢~然而,生活又给我一记耳光!
第二天看数据的时候,发现,咦,不对啊!62w数据怎么只抓了2w多记录,emmmmmmm 好吧,这次是Web Scraper崩溃了……
重新写代码
经过4天,我手头仅有2w数据,分析是够用了,但我还是不满意,想把完整的62w网站抓完,看看到底有多少个标签。为此,我拿出了吃灰已久的笔记本,写出了下面的代码。
1 | import urllib.request |
当然,这个代码是经过调优后的版本,中间也遇到了不少坑,比如刚开始用的不是urllib库,但因为以前的库只要断网控制台就报错,所以换掉了。还比如知乎反爬虫的问题,不仅仅是ip判断,还有浏览器头啊之类的。还比如window 7 下爬虫不工作问题。
因为还有其他工作,这个代码断断续续写了一天,终于在腾讯云 Windows 2012 server 服务器上跑通了!!!但是IP问题没解决,所以我又在淘宝上买了一个拨号VPN,通过result = os.system("rasdial VPN 41887 1111")这行代码去连接vpn,并在跑完1000个网站后断掉,获取新的IP。
为了方便后续检查,所以通过 doc=open('out.csv','a')命令将正常访问的地址导出到out.csv文件。同时设置了自动循环,从19590000循环到20210200。
代码中您可能看到不懂几个点,我解释下,比如:
- 为什么代码中开头是
star = 19590000,stop = 19591000而不是19590000和20210200?这块我为了让其保持1000的区间,后续通过star_stop = stop - star frequencys = star_stop * frequency stars = star + frequencys stops = stop + frequencys代码就能实现从19590000自动叠加到20210200. - 为什么
for frequency in range(621): if frequency < 621:是621而不是其他数字?只有621能让代码循环到20211000,其他数字不是高了就是低了,试出来的。 - 爬虫只抓取了url,没抓取内部的信息,这块当时写的心累,先把url抓出来再说吧。
这样写出来的爬虫相比于Web Scraper稳定多啦!CPU和内存占用也少到不知道哪里去了。就是效率有点低,算了下要抓4天才能搞定。本想提升效率,使用多线程或者多进程,然而……python的软肋就在这里,查了下资料说python的多进程不支持windows,多线程只能用单核……还有什么线程锁,好吧……效率还有可能更低……那我安安心心跑代码了,不再考虑什么效率了。心灰意冷.jpg
数据分析
PS:数据分析绝对不是我的强项,最多就会拿个Excel排个序画个图的这个样子,大佬看到请勿喷。
PPS:只抓了2W,数据不全,可能分析有偏差,等新的数据出来后,我会第一时间分享啦!
上面的代码爬虫至少需要4天才能搞定,不想等了,那么。手头的2W数据我能拿来干什么呢?哈哈哈,分析下吧!
我对关注数Top 100做了分类,暂且分为生活、学习、职业、技术这四大分类:
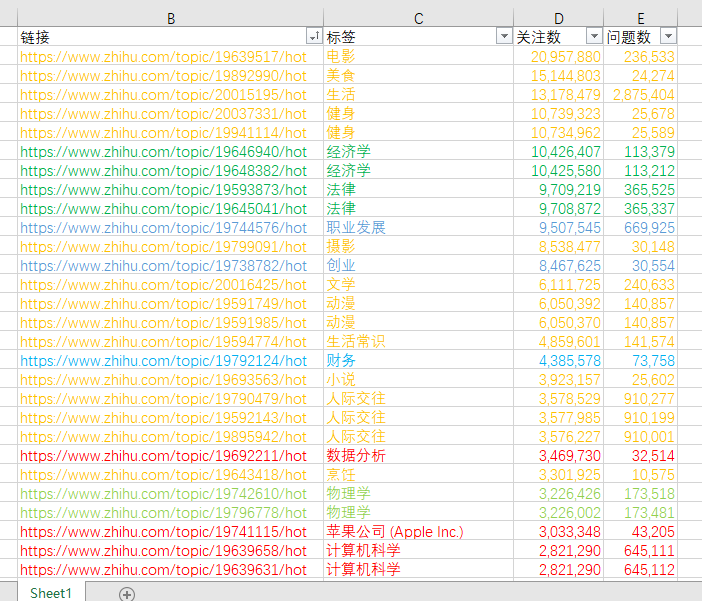
又对各个分类的TOP 10 做了排序,具体如下:
生活
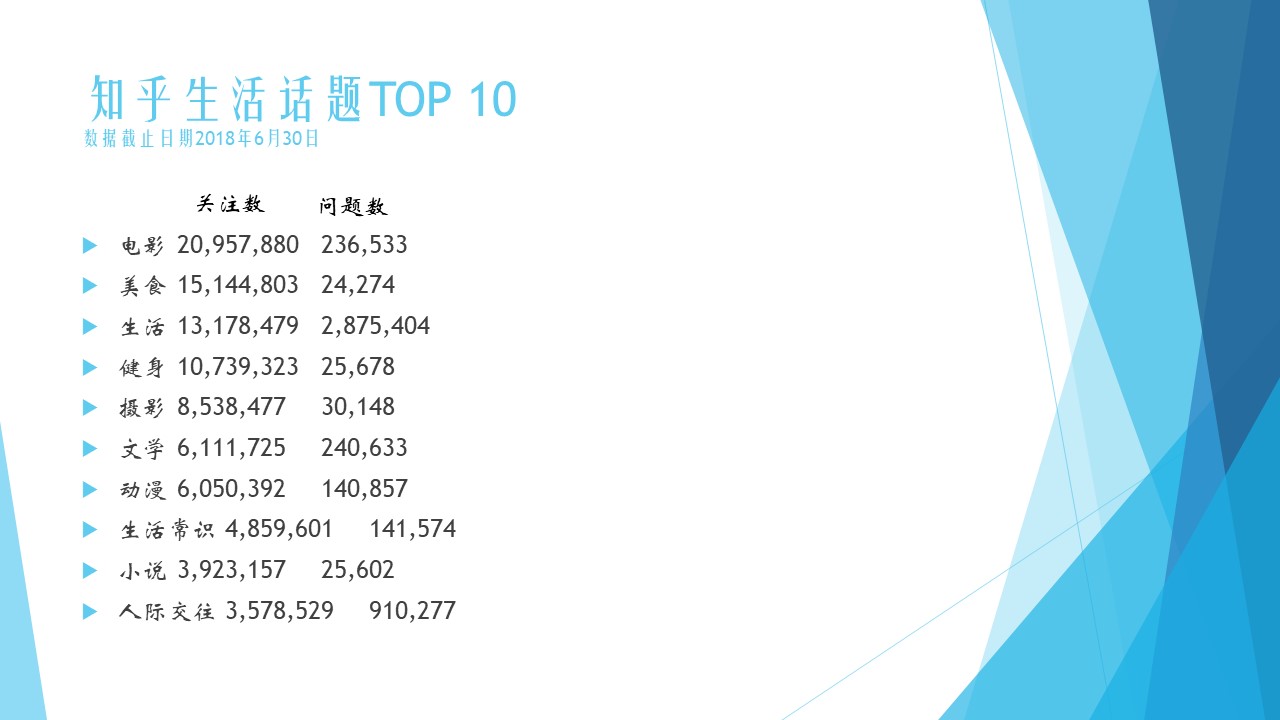
生活类话题电影和美食关注人最多,看来知乎还是“肥宅”比较多呀~看来不止是陈奕迅需要健身,大家也需要呢。知乎的用户都很喜欢生活,摄影也竟然有853w人关注!生活TOP10都是赚钱的事情呢·
学习

没想到经济学排了第一,哈哈哈看来我当年应该去学经济(逃。看来关注知乎的有很打一部分都是学生群体,很关注大学体验呢~学习类TOP10我个人是有点意想不到。
职业

不管是新工作的职场小白还是职场老鸟,大家都很关注自己的职业发展呢也祝大家能够尽快突破自己的行业天花板加油,不想当领导的领导不是好领导~
技术

这两年大数据很火呢数据分析竟然排了第一,而且,知乎的美工同学是不是比较多呢哈哈哈,平面设计和Photoshop竟然也有这么多人在看~
对我来说,这次抓取真的是学到了很有趣的东西,也了解了知乎用户的大致方向,希望后面能够通过这些数据去刺激用户去阅读相关文章。
数据分析个人不是太满意,首先是抓取的太少,应该不到总数的三分之一,其次是专业限制,不能太好的去分析这些数据。希望有同学看到本文能一起去做后续的分析工作,文末我会将本次的2w数据分享出来。剩下的数据我会抓完后和感兴趣的小伙伴一起去写一篇文章,再次打个广告!!!有数据分析相关专业的小伙伴请私聊我!一起去写后续的文章!
感谢您的阅读!