

我最近从巴西的里约热内卢搬到了加拿大的温哥华。除了美丽的风景以外,当头一棒的就是当地的房租价格了。温哥华目前是全球五大最贵房租城市之一。物业的租金表明,拥有固定资产是多么的奢侈。
我决定启动一个可以挖掘当前房屋数量的爬虫项目,我希望对目前温哥华房地产市场有一个自己的结论。话说有一堆很好的数据就在网上,我为什么不能去收集这些数据呢?
本文将从架构、成本、优点、缺点、及基于AWS(Amazon Web Services)无服务器架构的方向向您介绍爬虫项目。
等等,你说“没有服务器?”
众所周知,你在服务器上运行的所有数据都会在一天结束的时候由服务器进行自动备份。这里的无服务器的意思是你不必维护任何服务器或者虚拟主机。
诀窍就是使用SaaS服务(AWS Lambda,DynamoDB,RDS MySQLCloudwatch等)构建您的项目,然后让他们以一种非常“聪明”的方式进行工作。
准备好了吗?
项目架构
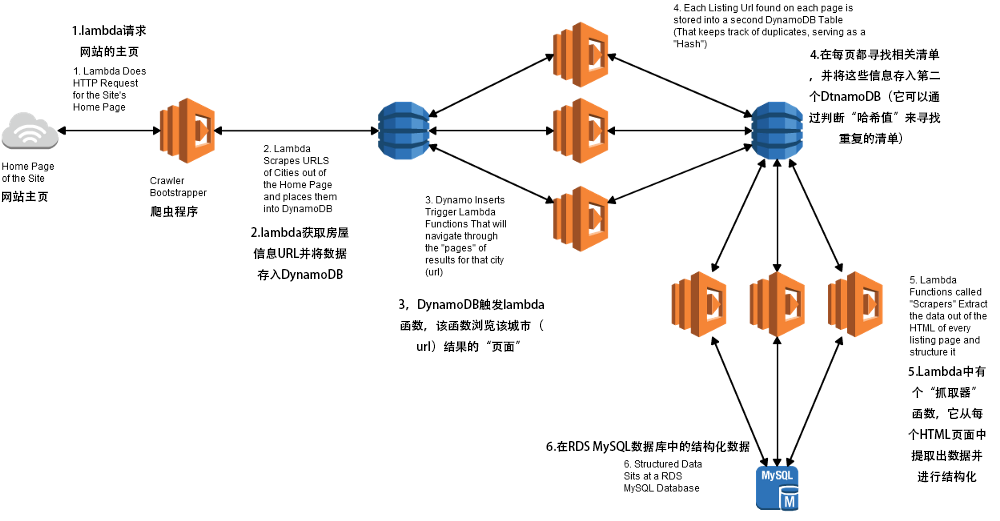
如果您不熟悉这些服务,我这里帮您做了个汇总:
- AWS Lambda:
- 在云上运行短期存在的函数
- 如果这些函数被调用或者触发,他们就会启动,写入并运行您的项目。项目运行后函数立刻销毁,你只需要为这个功能付出数秒的时间。
- DynamoDB:
- 完完全全在云上运行您的NoSQL数据库
- 您可以使用JOSN数据来做读取及写入,并将数据存储在您无需维护的服务器上。您可以在数秒内扩展您的数据库吞吐量。2017年初,DynamoDB开始支持TTL(生存时间)机制,这样您可以在您的存储对象达到TTL时间后自动被销毁。
- RDS MySQL:
- 完完全全托管在RDS(关系型数据库)上的云MySQL数据库。
- 弹性伸缩,可以根据您所需的功能进行备份。最近数据库提供了一个新的启用和停止功能。它允许您将您的项目实例停止长达7天之久。而您也只需要支付实际的使用量,而不是按照小时去付费。
- CloudWatch:
- 在云上监控记录您的项目
- 您可以免费使用该功能,从Lambda上运行Python的日志都会记录到您的CloudWatch中。
项目目标
在这个项目开始之前,我有几个目标。定好目标后我才能开始即兴创作。我的项目不得不完成以下几个目标:
- 完完全全在AWS上管理项目,不需要服务器。
- 项目所需资源负载均衡,弹性伸缩。
- 至少能够处理上万数据。
- 便宜
成本分析
使用Lanbda和CloudWatch都是免费的,除非你一直使用这两个功能,那你将面对一个不小的账单,但是目前对我这个项目来说,够用了。
对于DynamoDB和RDS MySQL,您将每月支付不到三美元来维持正常的工作。当您不使用的时候,您可以连续7天停止RDS数据库,并将DynamoDB缩小到最低的读取写入。
我估算成本为2.40$/月,可以查看我的项目来获得更多信息。
项目流程
整个项目从头到尾大概花费了我19个小时,这可能会根据大家对AWS和Python所熟悉的程度不同来影响具体的时间。我对AWS和Python都比较熟悉,但是不熟悉Dynamo和Lambda服务。
Lambda函数设置需要适应,但是当考虑到可用性等指标的时候,它与其他AWS服务一样稳定。
一旦你将流程在本地编辑Python文件——>创建一个.zip包——>上传 变为 Lamdba函数——>保存测试开发流程的时候,你会发现Lambda的优势。
当不知道你的lambda在HTTP请求失败后,遇到了什么问题,或者你陷入死循环中,你就会发现CloudWatch优势。
AWS还提供设置环境变量功能,调整资源设置超时,启用或禁用测试功能,整个设置简单友好。而且您不用每次都部署您的功能。另外我注意到Lambda函数运转速度非常快,几乎感觉不到延迟,我猜AWS为它设计了某种ECS智能缓存。
设置DynamoDB数据库可不是一件简单的事情,比如有一个提示设置,您需要填写两个数据框,设置的表名和表的分区,并为表设置TTL功能。但是你不能经常去改这个配置,它会阻止你来回切换,并删除你的数据记录。测试中我发现使用DynamoDB是正确的,当我插入Lambda函数时候基本没有任何延迟,想更改单个表的容量也是非常简单的事情,AWS几秒内就会帮你部署好整个环境。
配置RDS MySQL肯定比Lambda简单,但是与DynamoDB相比,多了很多步骤。你可以设置实例类型,卷的大小、冗余、维护窗口、备份时间等,一旦设置完成,AWS将在10分钟内部署好你的MySQL数据库。
安装和测试阶段结束后,我将会有一个放松的空闲时间,坐下来喝杯酒,睡一觉。为什么呢?因为数据爬取存入MySQL的过程太慢,我需要耐心等待。
DEBUG
展示效果并不是我的目标,修复技术缺陷是一件很酷的事情。但是我没想到这个爬虫会这么慢,每六小时大概能够爬取11000个清单,平均每2秒爬取一行数据。我以前写的分布式爬虫效率是这个三十倍,不过他们可没有这样令我激动。
每页的HTTP请求需要0.7~1.1秒,每个lambda函数转换时间加上MySQL存储时间,大约需要两秒。每个Lambda函数收到Dynamo的数据去处理大约需要7秒。
可以做一些优化,并行执行每个HTTP请求,并将数据插入MySQL。
说到并行处理,这个是我最不娴熟的技术。我是这样想的,在每一次数据插入Dynamo时都会立即触发一个Lambda来处理,这意味着Lambda只要能跟上Dynamo的速度,我就可以同时运行几十个函数来处理这些数据。但是,我错了 。
真实的情况是,Lambda有一个并发限制,这与DynamoDB有多少分片有关,由于我的DynamoDB只有一个分片,所以只有一个Lambda函数在运行。我的数据是这样的,我的DynamoDB即使插入某个数据花费了几分钟,完成后我的Lambda新函数才会执行,慢慢的,一个接一个的去处理,所以依然是通过串行的方式去处理数据,而并非并行。
在DynamoDB变更数据都会触发Lambda函数运行,但是这种更改可能不仅仅只是插入、删除、TTL更新都会触发Lambda函数。幸运的是,每次DynamoDB都会有标记,所以我可以利用这个属性判断数据是否被插入、更新、或者删除。所以我的Lambda设置仅处理插入。
优点和缺点
优点
- 便宜
- 完全托管/无服务器
- 卓越的技术
- 基础设施灵活
- 如果发现BUG,可以立刻修改lambda进行测试
缺点
- 慢
- 一旦开始执行,就不能停止工作。不支持断点续传。
- 代码上只能优化到这个层次
- 测试时你需要不断停用或者启用Lambda
总结
尽管整个项目非常有吸引力,如果你的项目需要性能和灵活性,而且需要随时改变架构和代码,我是不推荐你使用这种架构的。但是,这种架构非常便宜,能够胜任一些小的项目。可能设置会比较麻烦,一旦你需要别的需求,维护难度就非常大了。
项目已经写的非常好玩了,将所以东西黏在一起创造这个科学怪人。我会尝试再做一次,还是会坚持最初的目标,不过性能可能会提升不少。
最后,我通过多次运行这个程序已经拿到了40000的数据,我计划写一个新的代码来处理这些数据。目前来看,这个项目还暂时是一个demo。
非常感谢您阅读到这里,我已经编写了如何设置AWS账户的手册,而且代码处于开源状态,那就去破解吧!
代码我存储在Github上面,同时也发在我的博客上面,如果还想看看我接下来会做什么。就停下来看看~
我在个人页面上有自己的联系方式,您遇到任何问题都可以联系我,期待与你聊天。
下次见:)