
最近更新时间 2017年11月8日 14:58:51
本文翻译自freecodecamp 中Radu Raicea所发文章Want to know how Deep Learning works? Here’s a quick guide for everyone. 文中版权、图像代码等数据均归作者所有。为了本土化,翻译内容略作修改。
人工智能(AI)和机器学习(ML)是当今世界上最热门的话题之一。
“AI”这个词现在在互联网中飞来飞去。你不仅能在开发人员口中听到这个词,甚至有时候也会在产品设计运营人员中听到这个词。但是,他们真的搞清楚AI是什么了吗?所以,为了让更多人了解AI和ML,我写下本文。
本文适合所有人阅读,本文将不涉及高等数学及代码等相关领域的知识。
背景
了解深度学习第一步是掌握深度学习术语之间的差异。
人工智能与机器学习
人工智能是人类智能在计算机中的产物。
人类刚开始研究人工智能的时候,科学家就是尝试复制人类的智慧来完成特定的任务。
就拿玩游戏来说,需要让计算机了解并遵守游戏中大量的规则。计算机拥有一个详细的计划清单,并根据这些计划规则做出决定。我们将这个系统称为专家系统。
机器学习是指机器使用大量数据而非专家系统获得的学习能力。
ML(机器学习)允许电脑自己进行学习。这种方式利用强大的计算性能及大量的大型数据集,训练电脑认知某个事物。
监督学习和非监督学习
监督学习需要特定的输入数据及特定的预期输出结果。
当使用监督学习来训练AI时,你需要给它一个输入数据,并告诉它你的预期结果。
如果AI产生输出错误,它会对比正确的输出数据并重新调整内部算法。这个过程是需要迭代输入数据并判断输出结果,直到AI误差率降到很低。
监督学习一个很好的例子是天气预报,AI使用历史的天气数据(压力、温度、风速等)来预测输出的结果(温度,天气状况)
非监督学习是没有特定的结构数据的数据集进行的机器学习任务。
当使用非监督学习来训练AI时,您只用给AI一堆数据集即可,AI会对数据进行逻辑分类。
非监督学习很好的一个例子是电子商务网站用户购买行为预测,AI不会通过输入及输出来标记学习,反而会使用用户购买数据进行分类,并告诉你,那种用户最有可能购买那些产品。
那么,深度学习是如何工作的?
希望你已经准备好去了解深度学习的方法及它的工作原理。
深度学习是ML(机器学习)的一种方法。它允许我们使用特定的数据和方法(监督学习或者非监督学习)来训练AI(人工智能)。
我们还是通过想象在大脑中建立一个机票价格预测服务的模型来了解深度学习是如何工作的吧!为了更好的理解机器学习,这里将采用监督学习的方法进行讨论。
为此,我们需要以下输入数据(简单期间,暂时不考虑回程票):
- 出发地
- 目的地
- 出发日期
- 航空公司
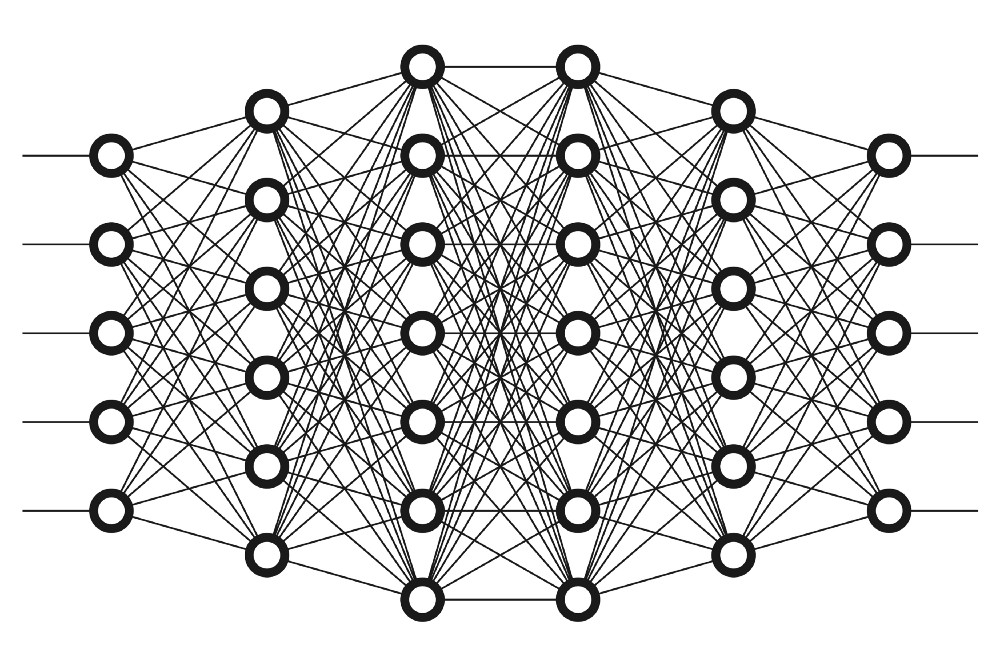
神经网络
开始之前,我们先看看AI的大脑。
正如同动物一样,AI也有类似神经元的东西,我们用圆圈表示每个神经元。这些神经元是互相连接的。
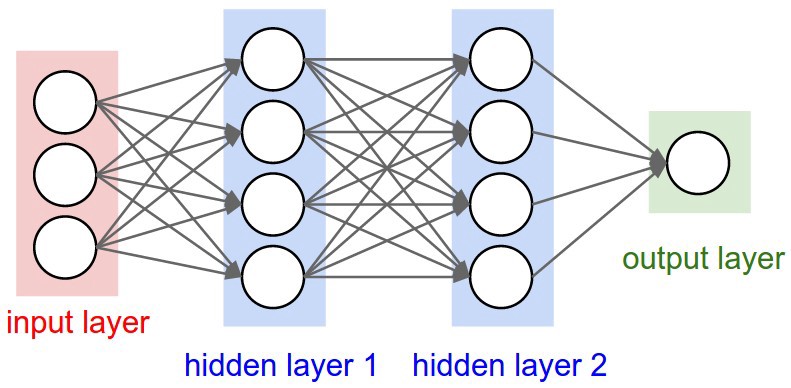
神经元被分三个不同的层:
- 输入层
- 隐藏层(多个)
- 输出层
输入层接收输入数据。在例子中,我们在输入层有四个神经元数据:出发地、目的地、出发日期航空公司。输入层将数据传给第一个隐藏层。
隐藏层中,我们需要考虑计算的方法。创建神经网络的挑战之一就是决定隐藏层才数量以及每层神经元的个数。有趣的是,深度学习中的“深度”就是指深度学习中有多少个隐藏层。
输出层负责返回数据,通过神经网络,我们就能预测出某个航班的价格。
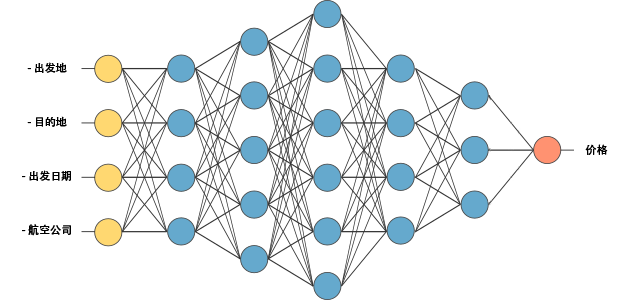
那么它是如何计算并预测价格的呢?
这就是深度学习魅力所在。
神经元之间的每一个连接都有不同的权重,这个权重决定了输入值的重要性,起初,这个权重是随机设置的。
通过数据对比,神经网络发现出发日期是比较重要的因素。因此,出发日期的权重慢慢就变得非常重要。
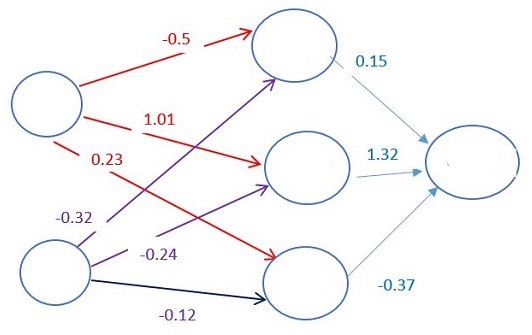
每一个神经元都有一个激励函数。没有数学推导的话,这些内容将很难理解。简而言之,激励函数的目的是标准化神经网络输出数据。
一旦一组输入数据通过神经网络,他就会通过输出层返回数据。
其实很简单,不是吗?
训练神经网络
训练是深度学习中最难的部分,为什么?
- 你需要大量的数据集。
- 需要强劲的计算能力。
对于机票价格的估算,我们需要找到票价历史的数据,但是因为机场和出发日期组合数量非常多,所以我们需要一个非常大的票价清单。
为了训练人工智能,我们需要给他特定的输入集,并将输出数据与真实的数据做比较。
一旦对比完整个数据集,就可以创建一个函数,告诉AI如何从真实数据中对比错误。这个函数我们称为损失函数(成本函数)。
理想情况下,我们的损失函数为零,AI输出数据与原始数据相同。
如何降低损失函数
最简单的方法是随机改变神经元之间的权重,知道损失函数数值变得很低,但是这种方法效率很低,不太实用。
为了解决这个问题,我们引入一个新的概念梯度下降。
梯度下降是一种方法,可以让我们找到一个函数的最小值,在本次案例中,我们正尝试寻找最低的损失函数。
当每次数据迭代后,以小增量的方式来改变权重,通过计算权重损失函数的导数(梯度),我们可以看到最小值的发展趋势。
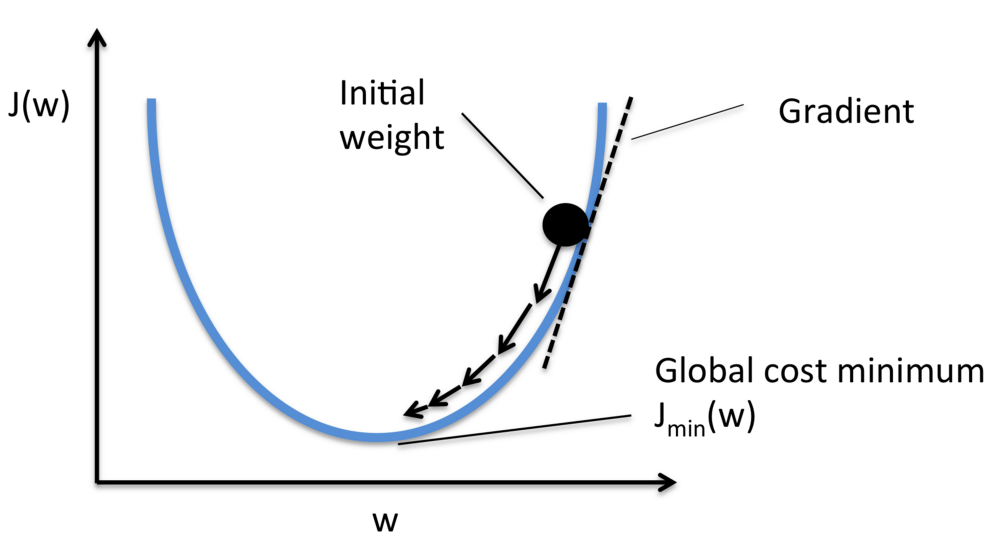
为了让损失函数达到最小值,你需要使用不同的数据进行多次尝试。这就是为什么你需要强劲的计算力了。
当然,神奇的是损失函数的更新下降是梯度下降的,由程序自动完成的。
一旦通过这样的训练得到了比较好的模型,那么就可以通过他来预测未来航空公司的价格。
希望学到更多?
还有很多其他类型的神经网络:比如用于计算机视觉处理的卷积神经网络和用于自然语言处理的回归神经网络。
如果你想了解深度学习方面的技术,我建议参加在线课程。
目前,深度学习最好的课程是Andrew Ng的深度学习课程。如果你对获得证书不感兴趣,你可以免费体验这个课程。
如果你有任何问题,或者想了解深度学习相关的技术概念,可以回复本帖。
总结
深度学习使用神经网络模仿动物的智力。
神经网络有三种神经元层:输入层,隐藏层,输出层。
神经元之间的链接与权重有关,权重规定输入值的重要性。
神经元将激励函数用于数据,并以“标准化”神经元输出。
神经网络需要大量的数据集。
迭代比较真实数据将产生一个损失函数,标识AI与真实数据偏离了多少。
通过数据集的每次迭代,使用梯度下降来调整神经元之间的权重,从而降低损失函数数据。
如果你喜欢这篇文章,请给我一些鼓励!让更多人看到它,谢谢!
你还可以看看我是如何通过Python来寻找有趣的人。
想了解更多信息?请在Twitter上关注我。